技术博客
分享人工智能安全领域的技术文章与经验总结
-
 本文对 PE-RLHF(物理增强人类反馈框架)与 CoFe-DIRL(无冲突深度模仿强化学习)两篇论文进行联合分析。前者用物理规则兜底人类反馈的不可靠性,后者在优化层面消除 RL 与 IL 的梯度冲突。两篇论文从不同角度探索了自动驾驶中安全性与灵活性的协同问题。
本文对 PE-RLHF(物理增强人类反馈框架)与 CoFe-DIRL(无冲突深度模仿强化学习)两篇论文进行联合分析。前者用物理规则兜底人类反馈的不可靠性,后者在优化层面消除 RL 与 IL 的梯度冲突。两篇论文从不同角度探索了自动驾驶中安全性与灵活性的协同问题。 -
 本次组会由王佳琪同学汇报了三篇AI安全领域前沿论文:USENIX Security 2025的Shadow Hack、DEF CON 24的传感器非接触攻击、CCS 2017的DolphinAttack。
本次组会由王佳琪同学汇报了三篇AI安全领域前沿论文:USENIX Security 2025的Shadow Hack、DEF CON 24的传感器非接触攻击、CCS 2017的DolphinAttack。 -
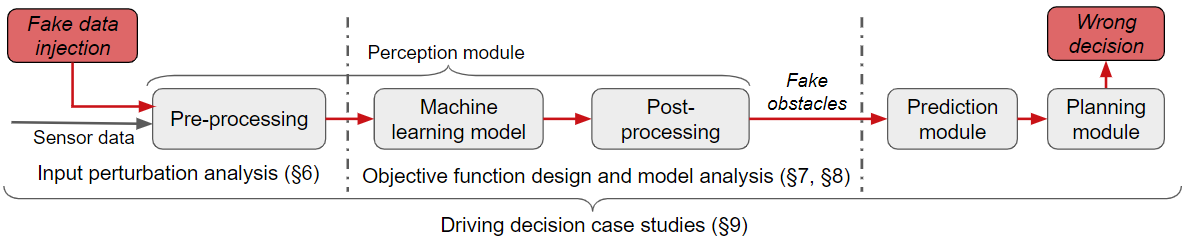 本文对两篇安全顶会论文进行完整的逐页联合分析:CCS 2019 的 Adv-LiDAR(激光雷达感知欺骗攻击)与 USENIX Security 2020 的 Light Commands(激光语音注入攻击)。两篇论文均利用光学物理效应对 AI 感知系统发起攻击,分别针对自动驾驶环境感知和语音助手的认证链路,揭示从物理层到应用层的完整攻击面。
本文对两篇安全顶会论文进行完整的逐页联合分析:CCS 2019 的 Adv-LiDAR(激光雷达感知欺骗攻击)与 USENIX Security 2020 的 Light Commands(激光语音注入攻击)。两篇论文均利用光学物理效应对 AI 感知系统发起攻击,分别针对自动驾驶环境感知和语音助手的认证链路,揭示从物理层到应用层的完整攻击面。